

今年年初,我们进行了多项实验,旨在降低 Shopify单体中 Ruby 垃圾收集器 (GC) 的延迟影响。本文中描述的一切都是团队的努力,非常感谢Jason Hiltz-Laforge对我们生产平台的扩展知识,感谢Peter Zhu对 Ruby 垃圾收集器的深入了解,以及Matt Valentine-House和étienne Barrié和Shane Pope对这项工作的贡献。
在本文中,我们将讨论我们为提高 GC 性能所做的更改,更重要的是,我们将讨论如何实现这些更改。
这项工作包括几轮改进日志记录和指标,解释它们以围绕有益的变化形成假设,测试和交付该变化,然后评估它是否应该保留、调整或恢复。
虽然本文中的叙述可能让我们看起来像是直接从问题到结果,但其中存在几个死胡同、不正确的假设和未产生预期结果的实验?。正如您对动态复杂系统的优化练习所期望的那样。
注意事项
在我们开始讨论我们所做的更改之前,我真的想强调,在没有先建立适当的方法来衡量此类更改的影响之前,您不应该盲目地在您的应用程序中应用 GC 设置。修改 GC 设置可以从根本上影响应用程序的性能,无论是正面的还是负面的。
Ruby 的默认 GC 设置相当不错,并且对于绝大多数 Ruby 应用程序都表现良好,因此我强烈建议不要调整它,除非您有强有力的证据证明它会显着影响您的应用程序的性能。
话虽如此,让我们来解决问题。
Shopify 的 Monolith 存在垃圾问题
在 Ruby 中,一切皆对象,几乎每个操作都会创建一个或多个对象。这些对象不会被程序员主动释放——当一个对象不再被引用时,它会被 Ruby 的垃圾收集器释放。
它是如何工作的是一个深刻而复杂的话题,我们不打算在这里尝试完全解释。如果您想深入研究,有很多很棒的文章。
但总的来说,我们可以说 Ruby 有一个保守的、分代的、增量的、标记清除跟踪垃圾收集器。
这里要理解的关键是,当 Ruby 垃圾收集器运行时,所有其他执行都会暂停。因此,当垃圾收集器决定它需要做一些工作时,它通常会在请求的生命周期内这样做。这种垃圾收集工作导致客户请求的延迟增加,导致商家和买家等待答案的时间比其他情况下要长。
这是我们开始调查问题时每个请求在 GC 中花费的时间分布的 24 小时片段:
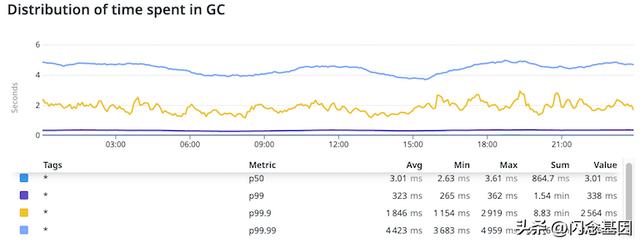
这些图显示了记录了 GC 信息的请求(占所有请求的 1%)在垃圾收集上花费的时间分布。该组中的平均请求花费 3 毫秒进行某种形式的垃圾收集工作,这完全没问题。p99 请求在垃圾收集上花费了大约 323 毫秒,这已经不是很好了。但是当我们接近尾端时,我们看到一些请求花费多秒来进行 GC 工作。这是我们要解决的主要问题。
世代垃圾收集器
分布看起来像这样的原因在很大程度上是因为 Ruby 的 GC 是分代的。0每个 Ruby 对象都有一个年龄,从第一次分配时开始。每次触发 GC 时,每个存活的对象都会增加其年龄。当一个对象达到最大年龄时3,它就会被提升到老年代。
然后当 GC 触发时,它可以根据多种启发式方法进行主要或次要标记。主要标记将标记所有对象,而次要标记将仅覆盖年轻对象,这些对象只是所有对象的一小部分。
因此,minor 标记非常快,在我们的例子中,如延迟图所示约为 3ms,而 majors 非常慢,超过 4 秒。
然而,因为 Ruby 的 GC 也是“增量的”,majors 并不总是在一个块中完成。GC 可以标记堆的一部分,然后让 Ruby 代码执行一小会儿,稍后再恢复标记。
我们的主要目标是降低主要标记的频率,因此我们必须首先找出触发主要标记的原因,然后解决该问题。
调整垃圾收集器
当我们开始这项工作时,应用程序已经在几年前进行了一些 GC 调优:
|
export RUBY_GC_OLDMALLOC_LIMIT="128000000" |
|
|
export RUBY_GC_MALLOC_LIMIT="128000000" |
|
|
export RUBY_GC_HEAP_SLOTS_GROWTH_FACTOR="1.25" |
|
|
export RUBY_GC_HEAP_GROWTH_MAX_SLOTS="300000" |
|
|
export RUBY_GC_HEAP_INIT_SLOTS="1600000" |
|
|
export RUBY_GC_HEAP_FREE_SLOTS="600000" |
|
|
export RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR="1.3" |
view rawgc_tuning.rb hosted with ? by GitHub
但显然,这些要么已经过时,要么不太正确。这些环境变量中的每一个都记录在 Ruby 手册页中,但我们将在本文后面更详细地解释其中的一些。
为什么会触发 Major Marking?
为了回答这个问题,我们开始记录GC.latest_gc_info(:major_by)上次主要 GC 被触发的原因。
我们观察到,大约 75% 的主要标记是由于 触发的:oldmalloc,而近 25% 的主要标记是由于 触发的:shady。
极限oldmalloc_
oldmalloc是分配的字节数的计数器。每次通过 malloc 分配内存时,分配的字节数都会添加到该计数器,一旦达到阈值,就会触发主要 GC。每次触发主要 GC 时,该计数器都会重置为 0。
Ruby GC 做出的假设是,如果旧对象一直频繁分配,则很可能它们的引用中存在一些变动,一些旧对象可能会被回收。
通过 可以查询计数器的状态GC.stat(:oldmalloc_increase_bytes),通过 可以查询触发major GC的限制GC.stat(:oldmalloc_increase_bytes_limit)。
也可以通过环境变量配置该限制,即:RUBY_GC_OLDMALLOC_LIMIT、RUBY_GC_OLDMALLOC_LIMIT_MAX和RUBY_GC_OLDMALLOC_LIMIT_GROWTH_FACTOR。
我们认为这种启发式与我们的工作负载类型并不相关,因此我们决定将其设置为荒谬的 128GB,这几乎可以禁用它:
|
export RUBY_GC_OLDMALLOC_LIMIT="128000000000" |
|
|
export RUBY_GC_OLDMALLOC_LIMIT_MAX="128000000000" |
view rawold_malloc_limit.rb hosted with ? by GitHub
我们必须同时设置LIMIT和LIMIT_MAX,因为通常情况下,每次limit达到 时,它都会增长,RUBY_GC_OLDMALLOC_LIMIT_GROWTH_FACTOR例如:
|
oldmalloc_limit = [ |
|
|
oldmalloc_limit * oldmalloc_limit_growth_factor, |
|
|
oldmalloc_limit_max, |
|
|
].min |
view rawold_malloc_limit_2.rb hosted with ? by GitHub
如果你眼尖的话,你可能已经注意到旧的配置RUBY_GC_OLDMALLOC_LIMIT_MAX根本没有设置,这意味着它实际上没有效果……
我们将这一变化应用于 50% 的生产过程,并立即注意到主要标记大幅减少了约 20%:
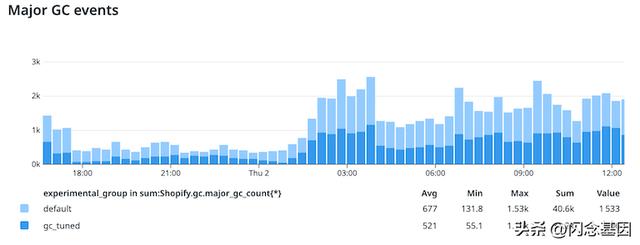
此时您可能想知道为什么没有减少 75%——这是因为火车可以隐藏另一辆火车。每当触发完整 GC 时,它都会重置大部分启发式算法,因此解决一个原因有时只会让另一种启发式算法更频繁地触发。
当我们查看 GC 原因的日志时,现在绝大多数是由nofree.
对象槽
要理解nofree启发式,您首先需要知道 Ruby 堆由槽页组成。当VM需要分配一个对象时,它会寻找一个空的slot来存放这个对象。如果没有slot可用,就会触发一个minor marking来腾出一些空间。次要标记完成后,如果没有足够的空闲插槽,可能会触发主要标记以尝试腾出更多空间。最后,如果这不起作用,将创建更多插槽。
原因nofree表明这种情况,所有这些限制也可以通过更多的环境变量来控制:
|
RUBY_GC_HEAP_INIT_SLOTS Initial allocation slots. Introduced in Ruby 2.1, default: 10000. |
|
|
RUBY_GC_HEAP_FREE_SLOTS Prepare at least this amount of slots after GC. Allocate this number slots if there are not enough slots. Introduced in Ruby 2.1, default: 4096 |
|
|
RUBY_GC_HEAP_GROWTH_FACTOR Increase allocation rate of heap slots by this factor. Introduced in Ruby 2.1, default: 1.8, minimum: 1.0 (no growth) |
|
|
RUBY_GC_HEAP_GROWTH_MAX_SLOTS Allocation rate is limited to this number of slots, preventing excessive allocation due to RUBY_GC_HEAP_GROWTH_FACTOR. Introduced in Ruby 2.1, default: 0 (no limit) |
view rawenvirontment_variables.txt hosted with ? by GitHub
一般来说,nofree发生在 Ruby 进程生命周期的早期。一旦过程稍微预热,它通常就会有足够的槽,可以不断回收。然而,Shopify 的单体应用大约每 30 分钟部署一次,所以除了周末,我们几乎一直处于“热身阶段”。
这个问题的解决方案是RUBY_GC_HEAP_INIT_SLOTS变量,它定义了 Ruby 在启动时应该立即分配多少个插槽。旧的 GC 配置预分配 1.6M 插槽。在生产中进行检测后GC.start(:heap_live_slots),我们确定我们需要接近 1500 万个插槽。
如果我们还在使用 Ruby 3.1,我们可以直接设置RUBY_GC_HEAP_INIT_SLOTS=15000000,然后我们就完成了。但是,我们在 1 月初升级到 Ruby 3.2,引入了可变宽度分配。
在 Ruby 3.2 中,现在有 5 种不同类型的插槽,您可以通过以下方式进行检查GC.stat_heap:
|
>> GC.stat_heap |
|
|
=> |
|
|
{ |
|
|
0 => { :slot_size=>40, :heap_eden_slots=>49120, …, :force_major_gc_count=>0 }, |
|
|
1 => { :slot_size=>80, :heap_eden_slots=>12276, …, :force_major_gc_count=>0 }, |
|
|
2 => { :slot_size=>160, :heap_eden_slots=>13900,…, :force_major_gc_count=>0 }, |
|
|
3 => { :slot_size=>320, :heap_eden_slots=>407, …, :force_major_gc_count=>0 }, |
|
|
4 => { :slot_size=>640, :heap_eden_slots=>408, …, :force_major_gc_count=>0 } |
|
|
} |
view rawgc_stat_heap.rb hosted with ? by GitHub
对于每个池,heap_eden_slots告诉我们有多少插槽空闲或正在使用,并force_major_gc_count告诉我们 Ruby 有多少次必须触发主要标记,因为它在该特定池中没有可用插槽。通过在生产中检测这些计数器,我们能够确定我们应该在每个池中预分配多少个插槽。
但是在 Ruby 3.2 中,如果你简单地设置RUBY_GC_HEAP_INIT_SLOTS,初始槽将根据它们的大小在所有大小的池之间分配:
|
RUBY_GC_HEAP_INIT_SLOTS=15000000 ruby –e 'p GC.stat_heap.values.to_h { |v| [v[:slot_size], v[:heap_eden_slots]] }' |
|
|
{ |
|
|
40 => 3_009_543, |
|
|
80 => 1_497_672, |
|
|
160 => 748_512, |
|
|
320 => 372_750, |
|
|
640 => 186_192 |
|
|
} |
view rawRUBY_GC_HEAP_INIT_SLOTS.rb hosted with ? by GitHub
这是有道理的,但这使得无法正确地预先分配我们需要的东西。在生产中热身的工人身上,尺寸看起来更像是:
|
40 => 11_500_000, |
|
|
80 => 2_500_000, |
|
|
160 => 1_400_000, |
|
|
320 => 260_000, |
|
|
640 => 180_000 |
view rawgc_heap_init_slots_example.rb hosted with ? by GitHub
使用 just 时RUBY_GC_HEAP_INIT_SLOTS,我们要么过度分配一些池,要么严重分配其他池,这确实是不可接受的。
实施细粒度预分配
为了测试在不浪费内存的情况下正确预分配每个池大小的有效性,我们设计了一个我们加载的可怕 hack config/boot.rb:
|
if ENV["SHOPIFY_RUBY_PREALLOCATE_SLOTS"] |
|
|
GC.disable |
|
|
ENV.fetch("SHOPIFY_RUBY_PREALLOCATE_SLOTS").split(",").each do |pair| |
|
|
size, slots = pair.split(":", 2).map { |i| Integer(i) } |
|
|
case size |
|
|
when 40 |
|
|
slots.times { Object.new } |
|
|
when 80 |
|
|
slots.times { Array.new(4) } |
|
|
when 160 |
|
|
slots.times { Array.new(10) } |
|
|
when 320 |
|
|
slots.times { Array.new(20) } |
|
|
when 640 |
|
|
slots.times { Array.new(40) } |
|
|
end |
|
|
end |
|
|
GC.enable |
|
|
GC.start |
|
|
end |
view rawconfigboot-hack.rb hosted with ? by GitHub
然后我们能够通过环境变量对其进行精细控制:
|
export SHOPIFY_RUBY_PREALLOCATE_SLOTS="40:11_500_000,80:2_500_000,160:1_400_000,320:260_000,640:180_000" |
view rawpreallocation-environment-variables.rb hosted with ? by GitHub
一旦我们部署了 dirty hack,我们就注意到了对 GC 尾部延迟的重大积极影响 ( gc_tuned_2):

我们多次调整数字以找到最佳点,但总的来说我们对结果非常满意,因此我们立即用适当的 Ruby 功能替换了 hack,并将其反向移植到我们自己的 Ruby 3.2 版本中。
我们对进展感到满意,但对花在 GC 上的总时间仍然不满意,所以我们继续挖掘。
阴暗的物体
我们查看的下一个主要标记来源是shady. 这个有点难以解释,因为它需要了解分代 GC 和 Write Barriers。
简而言之,要提升到老年代(因此只在专业上标记),Ruby 对象必须保证在更新它们对其他对象的引用之一时始终通知 GC。这就是我们所说的“写障碍”。它们的实现可能很棘手,任何被遗忘的写屏障都可能导致奇怪的错误,因为引用的对象可能被垃圾收集并且它的对象槽被另一个对象重用。正因为如此,仍然有很多 Ruby C 扩展没有实现写屏障,甚至一些核心 Ruby 类型也没有实现它们。
通常,当老对象开始引用年轻对象时,年轻对象会立即提升到老年代。但是如果被引用的对象没有承诺触发写屏障,那是不可能的,所以 GC 需要将那个年轻的对象保存在一个列表中,以确保在每个未成年人上标记它。这就是对象shady。
在 Ruby VM 内部,该术语shady已被替换uncollectible_wb_unprotected_object,但shady仍然是您将在 中看到的关键字GC.latest_gc_info。
由于这些物体正在减慢次要标记的速度,因此当它们积累太多以希望释放其中一些时,会自动触发主要标记。
与 with 一样oldmalloc,这些计数器可以通过GC.stat(:remembered_wb_unprotected_objects)and进行内省GC.stat(:remembered_wb_unprotected_objects_limit)。但是,此限制并不像其他限制那样真正可配置。
在这个阶段,我们可以引入一个环境变量来提高shady对象限制,但这意味着减慢次要标记以降低主要标记的频率——这不是一个令人愉快的折衷。因此,我们决定解决问题的根本原因,并开始对我们在生产中使用ObjectSpace.dump_all.
总的来说,我们向 Ruby 和各种流行的 gem 发出了将近 40 个 pull requests,太多了,无法在这里列出。但是为了了解它的含义,一些值得注意的是Time, BigDecimal, Method, oj, google-protobuf, ffi,
所有这些上游贡献都需要时间,因此我们在继续寻找其他 GC 调优机会的同时继续在后台进行这些工作。当我们开始这个项目时,我们的生产堆中有大约 160,000 个shady对象,在我们撰写本文时,它已经下降到大约 3,000 个,其中大部分来自google-protobuf我们ffi的修复程序合并后尚未发布的对象。
恢复带外垃圾收集
在这个工作阶段,我们没有多少 GC 调整旋钮可以转动。从一开始,我们的方法就是尝试消除造成主要标记的所有原因,但我们最终意识到这是不可能的。
一小部分应该在请求周期结束时释放的临时对象将不可避免地提升到老年代,只有主要标记才有可能收集它们。因此,主标记是 Ruby 进程生命周期中必不可少的部分。
因此,如果我们不能消除主要 GC,下一个最好的办法就是在进程当前未呈现请求时触发它。
这无论如何都不是一个新想法。它甚至在 Ruby 2.1 之前的日子里非常流行,当时添加了分代和增量 GC,但随着时间的推移,它因其吞吐量影响而失宠,通常被认为是一个已弃用的功能。
需要注意的是,历史上每次请求后都会触发带外 (OOB) 垃圾收集,事实上,我们的满分时间超过 4 秒,这将是一种巨大的资源浪费。
但考虑到我们之前发布的所有改进,我们不需要在每个请求周期后触发一个主要标记,偶尔触发一次就可以了。因此,我们决定以一个看似公平??的频率进行尝试——每 100 个请求一次——结果超出了我们的预期。
首先,请求周期中的主要标记几乎变成了一个边缘事件:
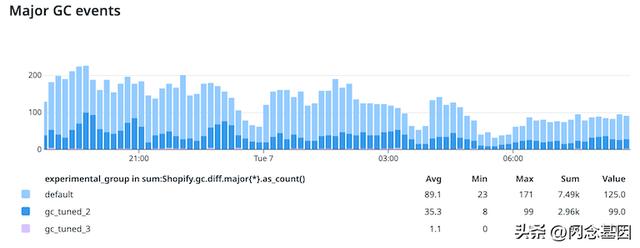
注意:default是此调优工作之前的原始 GC 配置,gc_tuned_2是我们当前的 GC 调优工作,gc_tuned_3是我们的新调优加上带外垃圾收集。
然后在 GC 中花费的最尾端(P99.99 和 P99.9)时间减少了近 10 倍:
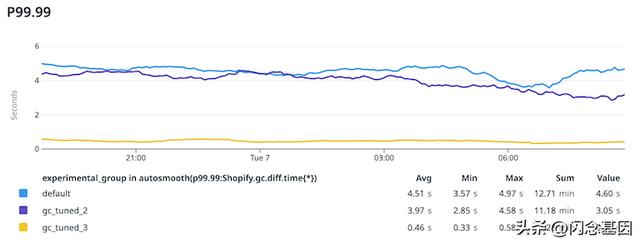
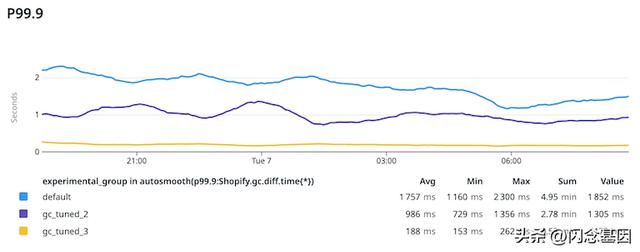
在 P99 上,它稍微温和一些,但仍然非常好:
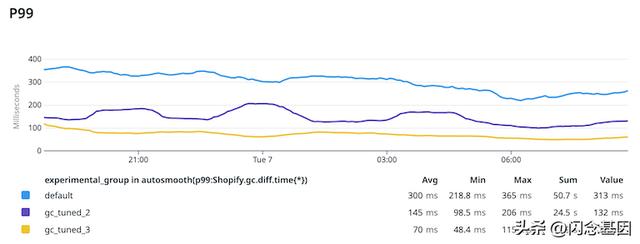
最令人惊讶的是,它基本上消除了中间请求的 GC 暂停:
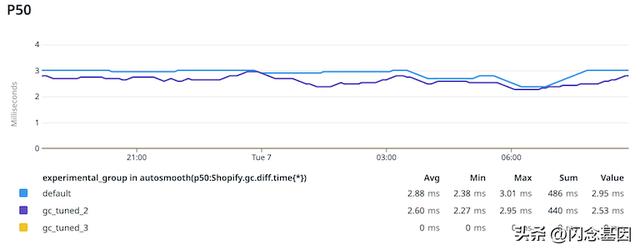
这不是我们想要的,但这是一个很好的惊喜。
然而,一个问题是额外的 CPU 利用率,因为从历史上看这就是 OOB GC 技术注定要失败的原因。100 个请求间隔纯粹是任意选择的,因此我们尝试了不同的间隔,并确定了一个可变频率,即每 128 个请求开始一次,随着进程的老化增加到每 512 个请求一次。
原因是最近启动的进程往往有一些不正确的预加载对象,因此当它们处理第一个请求时,它们往往会分配永远不会释放的对象。但是这些潜在的惰性加载对象的数量是有限的,所以随着进程变老,旧对象的数量趋于稳定,因此我们不需要那么频繁的 GC。
降低频率并没有以任何方式降低尾部延迟,但确实使每个请求的中值 GC 时间跳回到 ~2ms,我们发现这是可以接受的。尾部延迟确实是我们想要改进的。
我们也可以尝试比这更聪明,并尝试通过内省来猜测 Ruby 在下一个请求上触发主要标记的可能性有多大GC.stat,但我们还没有探索那个途径。
总结和展望
经过大约三周的努力,我们决定对结果感到满意,并将新配置应用于整个机队。
有趣的是,由于我们通常在 50% 或 33% 的生产队列上测试我们修改后的设置,我们的优化工作的进展可以在三周内在 GC 上花费的全球时间上看到:

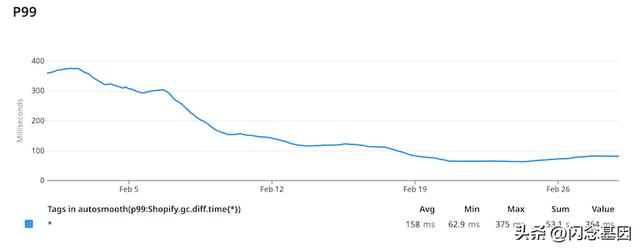
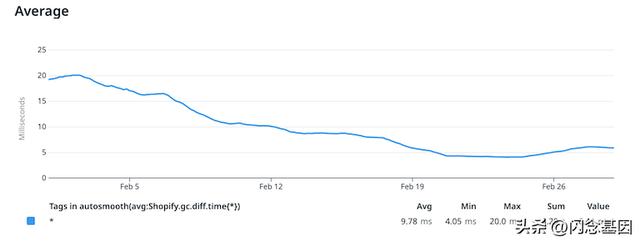
不过,我们并没有停止在 Ruby GC 上的工作。我们在这次调整工作中学到的东西启发了 Shopify 的 Ruby 基础设施团队的多个长期项目,以改进 GC 本身。
我们想要探索的一件事是引入一个新的“永久”生成的可能性,它可以容纳我们知道不可能收集的对象,并且有希望让主要标记变得更小。
我们也在寻找减缓年轻物体老化过程的方法。我们认为,一些较大的 API 请求往往会触发三个以上的次要标记,导致许多本应短暂的对象被提升到老年代。我们考虑引入一个“老化因子”,这样并不是所有的次要标记都会增加标记对象的年龄,或者允许在进程充分预热后完全禁止升级到老年代。
我们还想直接公开 GC 触发原因,GC.stat以便更容易检测。
也许其中一些会出现在 Ruby 3.3 中,谁知道呢。
作者:
Jean Boussier 是 Shopify 的 Ruby 和 Rails 基础架构团队的 Rails 核心团队成员、Ruby 提交者和高级工程师。您可以在 GitHub 上以@byroot 的身份或在 Twitter 上以@_byroot 的身份找到他。
出处:https://shopify.engineering/adventures-in-garbage-collection
天赐佳名网,国学周易八字百分美名,大师人工一对一起名添加 微信:stura998 备注:起名!
如若转载,请注明出处:https://www.tcjm99.com/15710.html
相关推荐
-
女人喷水到底是怎么回事儿,女人喷水到底是怎么回事
相互致意,泼水祝福,西双版纳的泼水节,一年一度的热闹。 故意骚扰,专泼下体,今年的泼水节习俗,似乎有些变味儿。 佳节已经结束,舆论争议却在持续发酵。当祝福致意变成了趁机揩油、搞性骚…
-
打开这款不停射爆的游戏,我冲了一天爽到起飞
狂丸研究所,每天涨点新知识 快快快,冲冲冲,喷射战士在行动! 最近,steam上一个名字别致的游戏横空出世,可能是因为名字起得太好,一经发售,就冲到了排行榜前五的位置,它就是魔性的…
-
一叶障目的故事告诉我们什么道理简写,一叶障目的故事
这几天农管遭到网友普遍热议,铺天盖地的都是一片质疑声。 农业综合行政执法大队是负责农业领域执法工作的机构。其组成主要分为领导班子、内勤办公室和执法人员。领导班子主要负责领导大队全面…
-
蒸糯米糕的家庭的做法,米糕的家庭的做法
酥软大米糕。喜欢酥酥口感的,可以再喷一点油。香酥米糕、奶香十足。 260克大米,加清水泡4小时以上。 泡好的大米:30克白糖、150克牛奶。 破壁机果蔬模式打两遍,很细腻。3克酵母…
-
支气管炎怎么治好的最快?治疗方法全面解析
支气管炎怎么治好的最快?治疗方法全面解析 [1] 概述 支气管炎是一种常见的呼吸道疾病,主要是由于支气管黏膜受到各种刺激,导致支气管的炎症和充血而引起的。这种疾病不仅引起人体的不适…
-
喜安智官网积分注册积分兑换(喜安智官方网站积分)
8月24日,由Morketing Global主办的Morketing Brand Globalization Summit 2022·第六届品牌全球化峰会在深圳圆满落幕。 本届峰…
-
鞋子晒黄了怎么洗白啊,网状鞋子晒黄了怎么洗白啊
一个人最基本的体面看鞋子,每天穿上合适的衣服配上一双干干净净的鞋,脚也舒服,整个人精神焕发,气质自信满满。各种各样的鞋子,比如说小白鞋,网面鞋,皮鞋,马丁鞋,绒面鞋等等,鞋虽然穿着…
-
本科电子信息工程专业考研方向,电子信息工程专业考研方向
Hello! 学弟学妹们大家好! 我是你们的日光学长, 今天来给大家分享 电子科技大学 电子信息 备考经验帖干货! 学姐/学长 基本信息 日光学长 专业方向:电子信息 初试350+…
-
女人叫床最好喊什么,女人叫床最好喊什么名字
问题:怎么才能每天都收到这种文章呢? 答案:只需要点击右上角“关注”即可。 流行周期律适用很多方面,称呼照样不例外,倘若使用过时的称呼跟日新月异的女人打交道,极有可能会擦肩而过。 …
-
熊出没之环球大冒险免费版全集(熊出没之环球大冒险104集免费观看在哪看)
#原创小说##不喜勿喷##謝謝# 第二集 神秘的传说 翠花问光头强:他说的那个人是谁. 光头强说:这个问题,有个人会认识,那个“人”(注意一下:不是指的人,是指的是动物). 翠花问…